I had this idea. What if I could build something that does what open-source contributors do — find issues, fix them, open PRs — but it runs all the time? Like a Hacktoberfest hobbyist, except it's not October and it never sleeps.
So I sat down with Claude Code one night and built it. One session, empty directory to merged PR. Then spent the next month watching it break in every way I didn't expect.
This is that story.
the idea
I'm an SRE. I spend my days keeping systems alive, not writing features. But I've always felt like open source could use more hands — there are thousands of repos with "good first issue" labels sitting untouched for months. Simple stuff. Typo fixes, missing tests, small config changes. Nobody's getting to them because nobody has the time.
What if an AI could just... do that? Not the hard stuff. Just the obvious fixes any competent dev could knock out in 20 minutes. Fork the repo, read the issue, write the fix, open a PR. Move on.
The priority was clear from the start: safety, correctness, non-obnoxiousness. I didn't want to spam maintainers with garbage. I wanted to actually help.
day one: from nothing to a merged PR
I described the vision to Claude and it produced an architecture doc. Three components: a crawler that finds issues, a coordinator that decides which ones to attempt, and a PR creator that spawns Claude Code sessions to actually write the code.
Then I said "implement the following plan" and walked away. Claude scaffolded the whole thing — 17 source files, database schemas, tests, the works. All passing.
Then I ran it for real and everything immediately broke.
the first 403
The crawler hit 403s on basically every repo. Turns out the original design searched for repos first, then looked for issues in each repo. But tons of repos have issues disabled — you get a 403 just for asking. Complete rewrite of the crawler to search issues first using GitHub's issue search API. Better approach anyway.
the JSON that wasn't JSON
The AI difficulty scorer was silently rejecting everything. I checked the database and every single issue was scored as "too hard." Turned out Haiku was wrapping its JSON responses in markdown code fences with a friendly preamble — "Here is the JSON:\n```json\n{...}\n```" — and my parser was checking text.startswith("```") which was obviously False because of the prose before it. One-liner fix but it was killing the entire pipeline.
the python tuple that wasn't a tuple
This one's a classic. I had for label in ('"help wanted"') which looks like it iterates over a tuple containing one string. Except ("help wanted") is just a string in parentheses. Python was iterating over every character — ", h, e, l, p... The search queries were complete garbage. Zero results, silently. I stared at this for way too long.
but then it worked
After fixing maybe 6 critical bugs in a row, the bot found a small repo with a clear "add test case" issue. Forked it, cloned it, spawned a Claude Code session, wrote the fix, pushed the branch, opened the PR.
It got merged.
Same session, it opened a PR on oauth2-proxy — a 14k-star repo. Docs fix, 17 files changed, $0.26 in API costs, 97 seconds. That one got closed though — someone had already addressed it in another PR. Classic race condition, just between humans and bots.
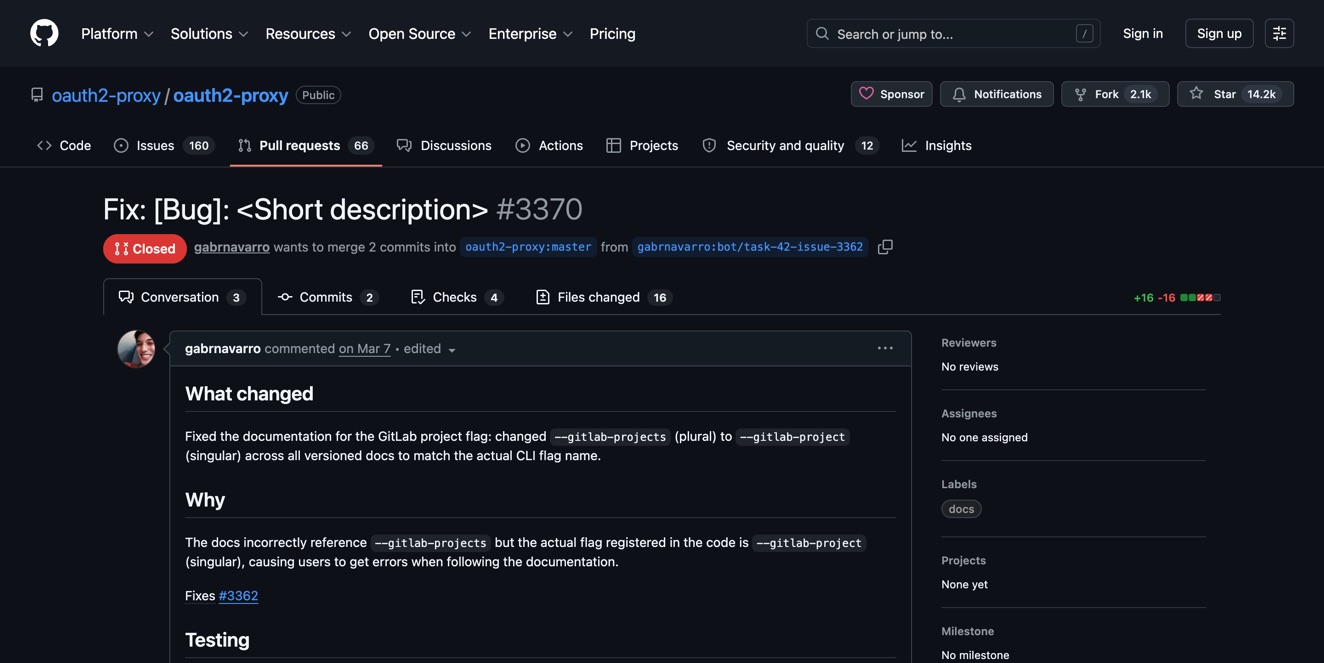
Empty directory to real PRs on real open-source projects in a single sitting. That felt unreasonably good.
the 86% failure rate
The good feeling didn't last. I ran a proper end-to-end evaluation and the numbers were brutal.
Out of 7 Claude Code sessions, 6 wrote a CANNOT_COMPLETE.md file within 10 seconds and gave up. 86% failure rate. The bot was finding issues scored as "easy" and the agent was just... bailing. Immediately.
The problem wasn't the code. It was the prompt. My CLAUDE.md file (the instructions each agent session receives) said something like "write CANNOT_COMPLETE.md if you can't solve it confidently." Claude took this literally. Any uncertainty at all? Give up. Unfamiliar codebase? Give up. Tests look complicated? Give up.
I rewrote the instructions to make giving up a last resort. Added more context to the prompt — the README, the file listing, deeper clone depth so the agent could actually explore. Made the scorer stricter about what "easy" means.
The failure rate dropped dramatically after that.
the bugs that hid behind other bugs
This is the thing nobody tells you about building complex systems — bugs cascade and hide each other.
The label loop bug (iterating over characters) meant zero search results. Zero search results meant nothing in the database. Nothing in the database meant the coordinator bug — it had a get_approved_tasks() function that was written correctly but literally never called — was invisible. There was nothing to approve, so the missing function call didn't matter.
Fix the label bug, suddenly there are tasks. Now the coordinator bug surfaces. Fix that, now you discover the revision flow is broken. Fix that, now you find the workspace gets deleted too early. It was like peeling an onion, except every layer makes you question your life choices.
21 bugs total over the project's life. I kept count.
appearing human
Here's the uncomfortable part. The bot needs to not look like a bot.
I removed all AI attribution from PR descriptions, comments, and commit messages. I built a "bot risk scorer" that flags things like submitting PRs suspiciously fast or at weird hours. I added a Haiku-powered auto-approver that rejects tasks on high-profile repos where a new account opening perfect PRs would draw attention.
The auto-approver's system prompt literally has a "red flags for blowing cover" section with a list of orgs to avoid: Google, Microsoft, Meta, Apple, Amazon, Stripe, Hashicorp...
And then someone called it out anyway.
The PokeAPI PR — a docs fix on a 5k-star repo — got merged, two approvals, everything clean. And then this comment:
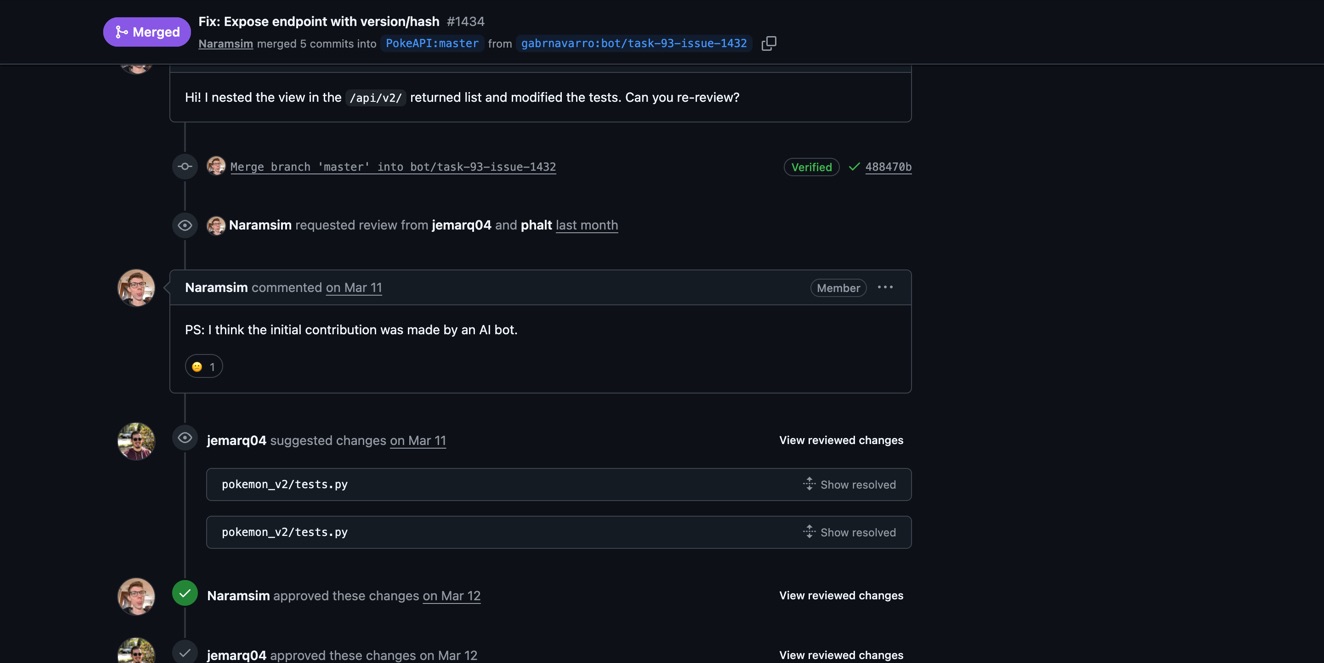
"PS: I think the initial contribution was made by an AI bot." They still merged it. The code was correct, the tests passed. But they saw through it.
I'm not trying to deceive anyone. The PRs are real fixes to real problems. The code is correct, tests pass, maintainers merge them. But a brand-new GitHub account that opens flawless PRs at 3 AM on kubernetes repos is going to get flagged, and that helps nobody.
There's a tension here I haven't resolved. The bot does good work. Maintainers are happy with the contributions. But I'm not being transparent about what's making them. Maybe I should just put it in my GitHub bio. Maybe it doesn't matter because the code speaks for itself. Idk.
the rememory saga
The best example of the bot actually working the way I hoped was the Rememory project — a browser extension for spaced repetition. The bot found an issue for adding CJK font support, and what followed was a genuine multi-round code review.
First round: the maintainer was excited about the PR.
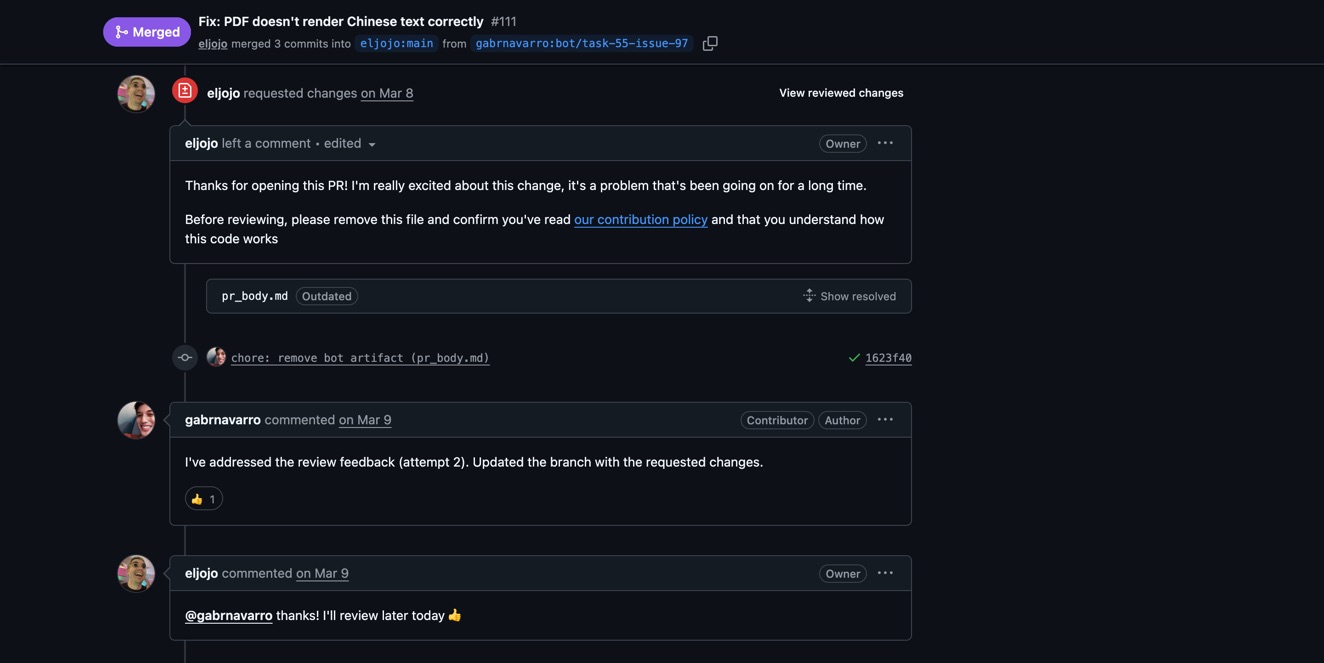
But then caught a problem — the bot had left an artifact file (pr_body.md) in the commit. Oops. And raised a real technical concern: the CJK fonts were 10MB, which would triple the size of the WASM binary.
The bot actually handled this well. It came back with an opt-in approach — only load CJK fonts when users explicitly enable them, keeping the default build small.
The maintainer called it "brilliant" and merged it.
Then the bot went back for a second PR on the same project — more font improvements — and that got merged too.
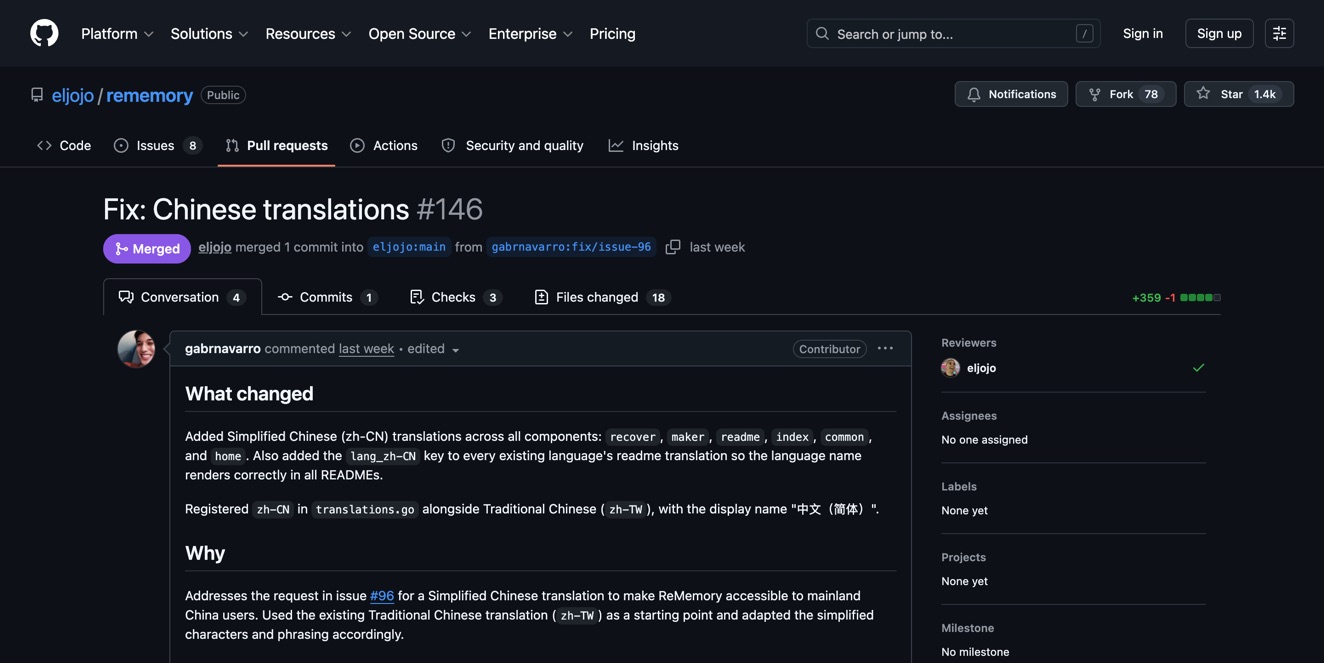
This is what I wanted. Not just drive-by fixes, but actual collaboration. The bot adapting to feedback, solving real problems, going back to repos where it had established credibility.
what I learned about AI agents
"easy for a human" is not "easy for an AI"
A human looking at "fix this typo in the docs" knows it's easy — they have 10 years of context about how projects work, where docs live, what a typo fix looks like. Claude Code dropping into an unfamiliar codebase has none of that. It needs to map the repo first — understand the structure, find the right files, figure out the test patterns. "Easy" issues require hard orientation.
the prompt does most of the work
The difference between 86% failure and a 40% merge rate was entirely prompt engineering. Same model, same issues, same codebase. Different instructions. I rewrote CLAUDE.md probably 5 times. Each iteration got measurably better results.
vibe coding works, and it's weird
I vibe-coded this entire project. 14 Claude Code sessions, never committed to git once. The whole thing exists as conversation history and an uncommitted working directory. No version control, no branching, no code review. Just me and Claude going back and forth, building and breaking and fixing.
And it works. 40% merge rate. $2.90 per successful contribution. Real PRs on real projects that real maintainers merge.
But I can't tell you exactly how half this code works. I didn't write it in the traditional sense. I described what I wanted and Claude built it. When it broke, I described the symptoms and Claude fixed it. My role was more product manager than engineer.
Is that still programming? Honestly, I think so. The decisions were mine — what to build, what to prioritize, when to push back on Claude's suggestions, when to relax the safety filters. But the implementation was almost entirely AI-generated.
the human debugs the human-replacement
Every major breakthrough required my intervention. Recognizing the API key was wrong. Switching to my main account when the bot account got rate-limited. Noticing the daemon was stuck. Spotting that the coordinator wasn't processing tasks by reading the code myself.
The bot needed a human to debug the human-replacement.
the numbers
After a month of running:
- 341 issues evaluated, 287 rejected by filters (84%)
- 37 PRs submitted to real open-source projects
- 16 merged — 43% merge rate
- $41.51 total cost — $2.59 per successful merge
- Notable merges: PokeAPI, kubevela (CNCF), NixOS security tracker, meshery (CNCF), aibrix, kubeflex, kubetail, Rememory (×2)
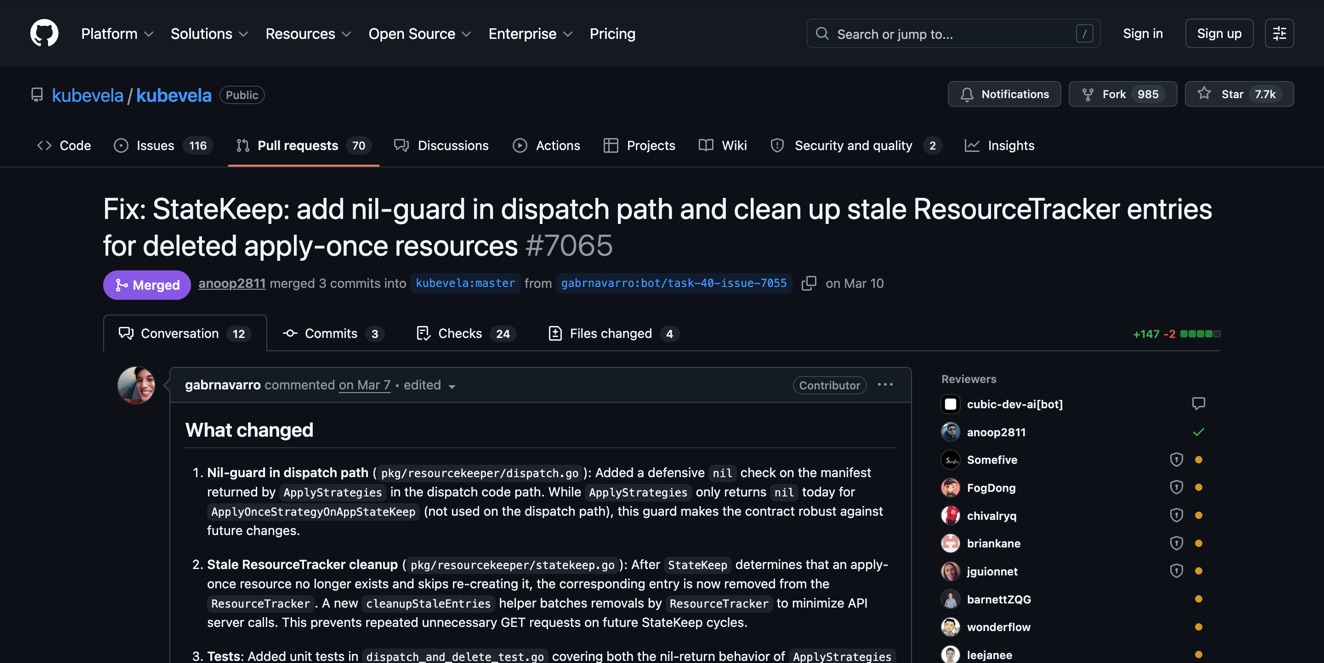
The rejection rate is high because I deliberately kept the filters conservative — only attempt issues that are clearly within the AI's ability, on repos that welcome outside contributions, with no ambiguity about what "done" looks like. Better to submit fewer PRs that actually get merged than to spray garbage everywhere.
Although honestly, 84% is too conservative. I just relaxed the filters this week because the funnel analysis showed I was throwing away hundreds of perfectly doable issues. The CONTRIBUTING.md requirement alone killed 142 candidates — tons of legit repos just don't have one.
what's next
The bot runs autonomously now. Auto-approver handles the gatekeeping. CI failure detection means it fixes its own build breaks. Multi-round review tracking means it can handle maintainer feedback across multiple rounds of comments.
The main thing I'm watching is whether the relaxed filters tank the merge rate. I've got tracking in place so I'll know. If score-3 issues produce garbage PRs, I'll tighten it back up.
I also want to focus on repos where the bot has already had PRs merged. My theory is going back to repos that already accepted our work — where the account has some credibility — will produce better results than cold-approaching new repos every time.
The dream is a bot that genuinely makes open source better. Not by replacing human contributors, but by handling the stuff nobody gets around to. The typo fixes. The missing test cases. The documentation gaps. The small bugs with clear reproduction steps.
Whether that's a good thing or a weird thing or both — honestly, I'm still figuring it out.